
-
<<
- Main
- Tutorial
- Field list
titlestorycodexrefapp fieldscredit fieldsdesc fieldscomment fieldschange fieldsminor credit fieldspage fieldspropagation fieldspublication date fieldsmisc. story item fieldsvarious story fieldsvarious entry fieldsvarious h1 fieldsvarious h2 fieldsvarious h3 fieldsname fieldstranslation fieldsfile fieldsmaintenance fieldsvarious movie fieldsvarious person fieldsvarious character fieldsvarious subseries fieldsvarious site fieldsvarious country fieldsvarious language fieldsvarious currency fieldsvarious dbh fieldsstoryheadercodeother fields
- ISV files
inducks_appearanceinducks_characterinducks_characteraliasinducks_characterdetailinducks_characternameinducks_characterreferenceinducks_characterurlinducks_countryinducks_countrynameinducks_currencyinducks_currencynameinducks_entryinducks_entrycharacternameinducks_entryjobinducks_entryurlinducks_equivinducks_herocharacterinducks_inputfileinducks_issueinducks_issuecollectinginducks_issuedateinducks_issuejobinducks_issuepriceinducks_issuerangeinducks_issueurlinducks_languageinducks_languagenameinducks_loginducks_logdatainducks_logocharacterinducks_movieinducks_moviecharacterinducks_moviejobinducks_moviereferenceinducks_personinducks_personaliasinducks_personurlinducks_publicationinducks_publicationcategoryinducks_publicationnameinducks_publicationurlinducks_publisherinducks_publishingjobinducks_referencereasoninducks_referencereasonnameinducks_siteinducks_statcharactercharacterinducks_statcharactercountryinducks_statcharacterstoryinducks_statpersoncharacterinducks_statpersoncountryinducks_statpersonpersoninducks_statpersonstoryinducks_storyinducks_storycodesinducks_storycreationdateinducks_storydescriptioninducks_storyheaderinducks_storyjobinducks_storyreferenceinducks_storysubseriesinducks_storyurlinducks_storyversioninducks_studioinducks_studioworkinducks_subseriesinducks_subseriesnameinducks_substoryinducks_teaminducks_teammemberinducks_ucrelationinducks_universeinducks_universenameinduckspriv_entryinduckspriv_issueinduckspriv_story
- Log msg.
- Dizni
- Producktion
- Indexindex
-
>>

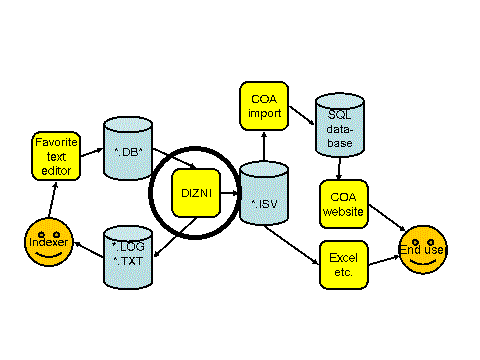 1. What can Dizni do for youIf you are an indexer, the program Dizni can do several things for you.The most important things are:
But first, a chapter about what we assume you already know, and a chapter about how to get the Dizni program. 2. What do you need to know before reading the restFirst of all, we assume you have read the previous "How to Index" pages on this website. So you know about "input", "internal", and "output" files.Secondly, you need to know something about command lines, batch files, and directory structures. For instance a DOS-box in MS-Windows. In the rest we'll just assume you are an MS-Windows user. Users of other operating systems (like Linux) are usually smart enough to read the text anyway. 8-) It's very handy when you know how to use SVN, but you can also do lots of things without. 3. Getting Dizni itselfThe file DIZNI.EXE is not directly available.You can try to compile the C++ source code of Dizni. The source code is available through SVN. The "make" instruction is very simple: compile *.cpp, and link all object files together. (There is a gnu-Makefile available that does just that.) There are also some example batch files (on SVN: inducks/programs/dizni/batchfiles/).These mainly illustrate what we're writing here. In the examples below, we're showing the contents of these batchfiles. The directories we use there are just an example. 4. Getting the input filesThe input files are all available on SVN. You can put the locally, for instance on a directory called c:\fluks\inducks.You need to create (mkdir) a directory like c:\fluks\i\data\. Dizni will put its internal and output files, as well as some scratch files here.You will need at least 350 megabytes of disc space for running Dizni the standard way (as described in the next chapter). 5. Generating the internal files5.0. Running Dizni the standard wayIf all input files are on their places, you can run:dizni -xx -C c:\fluks\i\inducks\ -D c:\fluks\i\data\ -sto generate the internal files in the directory c:\fluks\i\data\ (always end the directory name with a \).This generation can take a long time (though on HF's machine it takes less than 2 minutes). After the generation, you'll have a bunch of new files:
dizni -xx, you can add several options. The most interesting is -q, which tells Dizni to keep quiet (no messages on the screen).If the option -s is not given, the textual output files (*.txt) are not written.
5.1. Running Dizni with fewer filesIf you don't want to download all the input files, it's OK to leave most of them out.You can run Dizni anyway, but the results will be less, of course. There are only a few files that must exist when running Dizni. These are the DBX files on the SVN directory auxil (like legendfiles.dbx, countries.dbx, languages.dbx, storyfiles.dbx), except equivs.dbx and oldcodes.dbx.
Besides this, at least one DBI file and at least one DBS file must exist. 6. Dizni utilitiesIf you want to find out all options of Dizni, tryDIZNI -? on a command line.The output will give a list of main options. For every main option (for instance "x"), you can try DIZNI -xx -?.This will give you a list of all switches that you can use with that main option. In the following paragraphs, we describe the most used utilities. Other DIZNI options are mainly meant for HF only. 6.1 CheckequivThe call is:dizni -xuq -C c:\fluks\i\inducks\ -D c:\fluks\i\data\ -s -gThis option needs the DBX files, and all applicable DBI files. It writes a report to c:\fluks\i\data\equiv.log.This report can be used to spot errors. For instance:
Reporting equivalents of:
#de1 = de/LTB 301
#nl2 = nl/PO3 88
Not listed in all 2 issues:
D 98172/49 is(+) or is not(-) in: #de1- #nl2+
D 98172/50 is(+) or is not(-) in: #de1+ #nl2-
In this example, apparently the "nl" entry has a wrong page count (unless the issues are not fully equivalent, of course).
6.2 Language file checkThe call is:dizni -xut -c nl -C c:\fluks\i\inducks\ -D c:\fluks\i\data\This option reads the file heroes-nl.dbi and produces a file heroes-nl.cpy.This cpy file contains a checked version of all characters. Missing characters are added (with empty translation), while wrong character names are noted. 6.3 Check (and copy) DBI fileThe call is:dizni -xuc -f nl.dbi -C c:\fluks\i\inducks\ -D c:\fluks\i\data\ -c -hThis option reads nl.dbi and makes an "improved" copy of it (c:\fluks\i\data\nl.cpy).In this CPY file, the most obvious errors are automatically corrected (if the -c option is given).These corrections are also marked in the CPY file (if the -h option is given), for instance like this: [/`hero changed, was: D+M]It uses the DBL input files from the SVN tree, as well as the usual DBX files and oldcodes.dbx.The file nl.dbi should be on c:\fluks\i\data\, Dizni does not look in the SVN tree for it (because it cannot guess in which subdir the file is).
Error messages are written to dizni.log.
|